0. はじめに
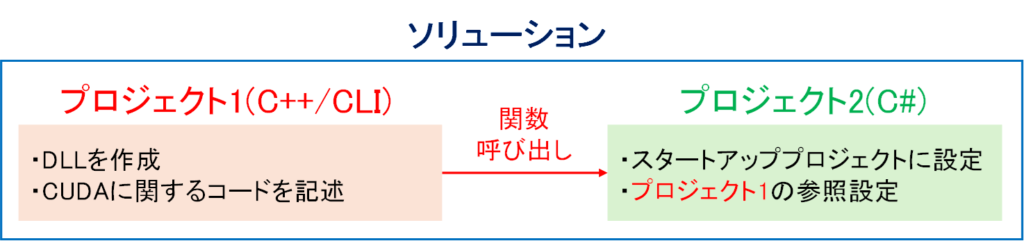
CUDAはC/C++のみをサポートしますが,C++/CLIを使うことでC#でもCUDAによる計算を簡単に実装できます.C++/CLIとはC++にC#のマネージドな機能を追加した言語で,C++やCUDAで記述したコードを,C#で呼び出せる形式のDLLとしてビルドできます.そのため下図のようにソリューション内でプロジェクトを分けてCUDAに関する処理をC++/CLIで記述することで,C#でもGPUによる並列計算処理を実装できます.
そこで本稿では,C++/CLIを活用して,C#においてCUDAでベクトル和を計算するサンプルプログラムを作成します.

ソースコード:https://github.com/kkaneko1090/CUDACLITest
1.事前準備
①Visual studio communityをインストールします.
②CUDAのインストールします.今回はCUDA Toolkit 12.3で実装します.https://developer.nvidia.com/cuda-toolkit
③ワークロードで「C++によるデスクトップ開発」をインストールします.
加えて,C++/CLIを使用するために,Visual studio Installerの個別コンポーネントでビルドツールをインストールします.CUDA 12.3では MSVC v14.3Xまでしかサポートされていないの下図の「v143 ビルドツールのC++/CLIサポート(14.39-17.9)」を追加しました.
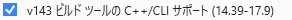
2.プロジェクト1(C++/CLI)の作成
最初に,CUDA関数を格納するDLLを作成するためのC++/CLIプロジェクトを作成します.下図のように,CUDA 12.3 Runtimeを選択して,まずはCUDAに対応したC++のプロジェクトを作成します.今回は,”CUDACLITest”という名前で作成しました.このC++(CUDA)のプロジェクトの設定を変更することで,C++/CLIの機能を使えるようにします.
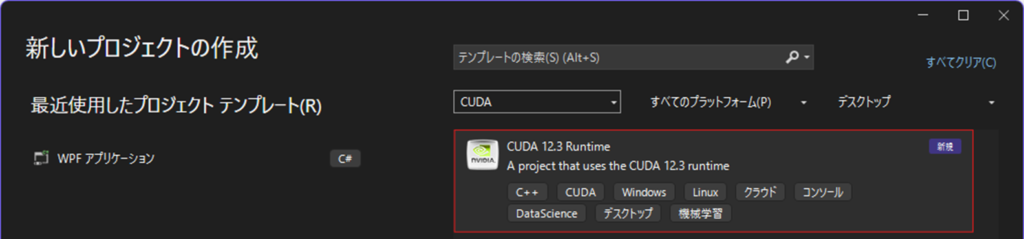
DLLを作成するためのプロジェクトなので,プロジェクトのプロパティで「構成の種類」をDLLに変更します.
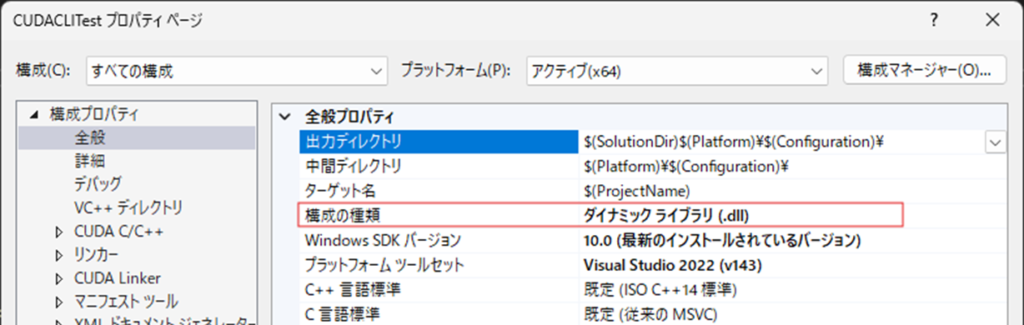
次にC++/CLIプロパティを以下のように設定することで,.Net 8.0をターゲットとしたDLLの作成が可能となります.
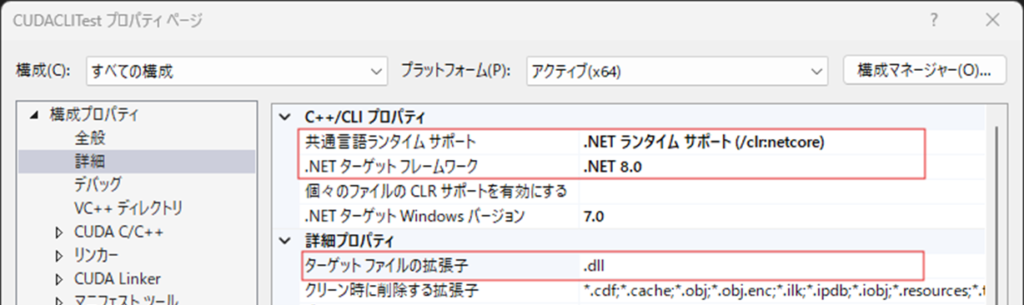
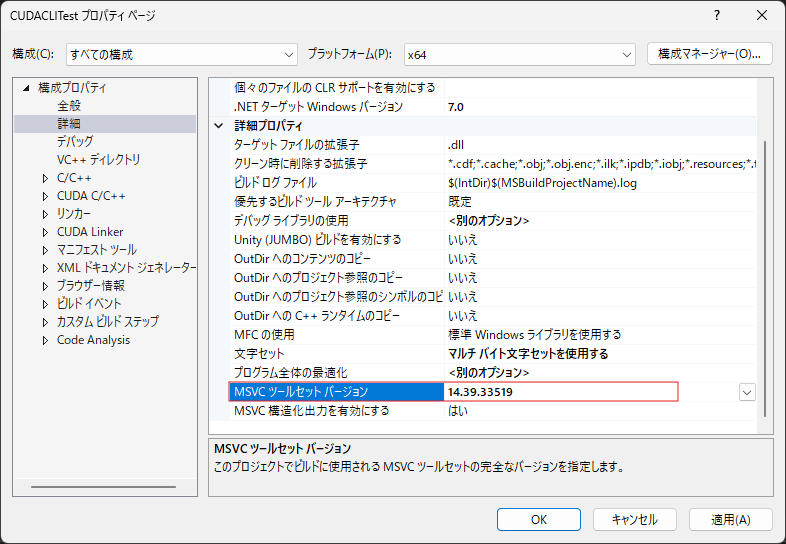
念のため,MSVCツールセットのバージョンを確認します.上記の通り,CUDA 12.3 ではMSVCはv14.3Xまでしかサポートされていないので,もしこれが14.4Xとなっている場合は,以下のように14.3Xに変更しないとビルドが通らない可能性があります.
3. ベクトル和を計算するCUDAコードを記述
以下のように4つのファイルでDLLを構築します.
①Kernel.cu・・・・・ベクトル和を計算するカーネル関数を定義
②Kernel.cuh ・・・・Kernel.cuのヘッダーファイル
③Calculator.cpp・・・カーネル関数を呼び出し,計算を実行する関数を定義
④Calculator.h・・・・Calculator.cppのヘッダーファイル
Kernel.cuでは,以下のように2ベクトルの和を計算するカーネル関数を記述しました.CUDAでの並列計算の仕様は,以下のプログラミングガイドを参照してください.https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
//Kernel.cu
#pragma once
#include "Kernel.cuh"
/// <summary>
/// ベクトル和を計算するカーネル関数
/// </summary>
/// <param name="vec_0">ベクトル0</param>
/// <param name="vec_1">ベクトル1</param>
/// <param name="result">計算結果のベクトル</param>
/// <param name="length">ベクトルの長さ</param>
/// <returns></returns>
__global__ void CudaAddKernel(float* vec_0, float* vec_1, float* result, int* length) {
//インデックス
int index = (blockIdx.x * blockDim.x) + threadIdx.x;
//インデックスが範囲内のとき
if (index < *length) {
//ベクトルの要素どうしを足し合わせる
result[index] = vec_0[index] + vec_1[index];
}
}Kernel.cuhはヘッダーファイルで,以下の通りです.
//Kernel.cuh
#pragma
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
/// <summary>
/// ベクトル和を計算するカーネル関数
/// </summary>
/// <param name="vec_0">ベクトル0</param>
/// <param name="vec_1">ベクトル1</param>
/// <param name="result">計算結果のベクトル</param>
/// <param name="length">ベクトルの長さ</param>
/// <returns></returns>
__global__ void CudaAddKernel(float* vec_0, float* vec_1, float* result, int* length);Calculator.cppでは,上記のカーネル関数”CudaAddKernel”を呼び出してGPUで計算を行い,計算結果を返すコードCalculator::Add(array<float>^ vec_0, array<float>^ vec_1)を記述します.今回は,ネームスペースをCUDA,クラス名をCalculatorとしました.クラスの定義において,public ref class となっておりますが,refを付けることでC#で呼び出し可能なクラスとして定義できます.
以下のようにCalculator.cppを記述しました.この関数の引数の型は,array<float>ですがこれは,C#におけるfloat[]と同義です.このようにC++/CLIではC#のマネージドな機能を使用できます.マネージドな変数には頭に^が付きます.
関数 “Calculator::Add” では,まずC#のマネージド配列 array<float> を C++ のアンマネージド配列 float* に pin_ptr を使って変換します.次はデバイス変数のメモリ確保とデータ転送を行っていますが,個々の処理は通常のCUDAと同様です.その後,カーネル関数を呼び出してGPU上で計算を行いますが,C++/CLI では通常の CUDA と異なり ”cudaLaunchKernel” によりカーネルを実行します.
最後にデバイスでの計算結果 d_result をホスト変数 h_result に転送します.そしてマネージドな配列に変換してからreturn で計算結果を返します.
//Calculator.cpp
#pragma once
#include "Calculator.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "Kernel.cuh"
namespace CUDA {
/// <summary>
/// 同じ長さのベクトルの和
/// </summary>
/// <param name="vec_0">ベクトル0</param>
/// <param name="vec_1">ベクトル1</param>
/// <returns></returns>
array<float>^ Calculator::Add(array<float>^ vec_0, array<float>^ vec_1) {
#pragma region ホスト変数の用意
//pin_ptrで配列を固定し、ポインターを取得
pin_ptr<float> vec_0_pin_ptr = &vec_0[0];
pin_ptr<float> vec_1_pin_ptr = &vec_1[0];
//アンマネージド配列のホスト変数を用意
float* h_vec_0 = vec_0_pin_ptr; //ベクトル0のアンマネージド配列
float* h_vec_1 = vec_1_pin_ptr; //ベクトル1のアンマネージド配列
float* h_result = new float[vec_0->Length]; //計算結果のアンマネージド配列
int h_length = vec_0->Length; //ベクトルの長さ
#pragma endregion
#pragma region デバイス変数の用意
//ホスト変数に対応した,デバイス変数を用意
float* d_vec_0; //ベクトル0
float* d_vec_1; //ベクトル0
float* d_result; //計算結果
int* d_length; //ベクトルの長さ
//デバイスを指定
cudaError_t cuda_status = cudaSetDevice(0);
//デバイス変数のメモリ確保
cuda_status = cudaMalloc(&d_vec_0, h_length * sizeof(float));
cuda_status = cudaMalloc(&d_vec_1, h_length * sizeof(float));
cuda_status = cudaMalloc(&d_result, h_length * sizeof(float));
cuda_status = cudaMalloc(&d_length, sizeof(int));
//ホスト変数の値をデバイス変数にコピー
cuda_status = cudaMemcpy(d_vec_0, h_vec_0, h_length * sizeof(float), cudaMemcpyHostToDevice);
cuda_status = cudaMemcpy(d_vec_1, h_vec_1, h_length * sizeof(float), cudaMemcpyHostToDevice);
cuda_status = cudaMemcpy(d_length, &h_length, sizeof(int), cudaMemcpyHostToDevice);
#pragma endregion
#pragma region カーネル関数の実行
//並列計算条件
int max_thread_num = 256; //最大スレッド数
dim3 grid(h_length / max_thread_num + 1); //グリッドの次元
dim3 block(max_thread_num); //ブロックの次元
//引数
void* args[] = { &d_vec_0, &d_vec_1, &d_result, &d_length };
//カーネル実行
cuda_status = cudaLaunchKernel((const void*)CudaAddKernel, grid, block, args);
//処理待ち
cuda_status = cudaDeviceSynchronize();
#pragma endregion
//計算結果のデバイス変数の値を,ホストにコピー
cuda_status = cudaMemcpy(h_result, d_result, h_length * sizeof(float), cudaMemcpyDeviceToHost);
//アンマネージド配列を,マネージド配列に変換
array<float>^ result_managed = gcnew array<float>(vec_0->Length);
for (int i = 0; i < result_managed->Length; i++) result_managed[i] = h_result[i];
//newで確保したメモリの開放
delete[] h_result;
//デバイスメモリの開放
cuda_status = cudaFree(d_vec_0);
cuda_status = cudaFree(d_vec_1);
cuda_status = cudaFree(d_result);
cuda_status = cudaFree(d_length);
return result_managed;
}
}以上がC++/CLIによる関数の実装になります.このプロジェクトをビルドすることでC#でも呼び出し可能なDLLを作成できます.
4. プロジェクト2(C#)を作成
以上のように実装したCalculatorクラスを使用するC#のプロジェクトを作成します.以下のように今回はコンソールアプリを選択しました.
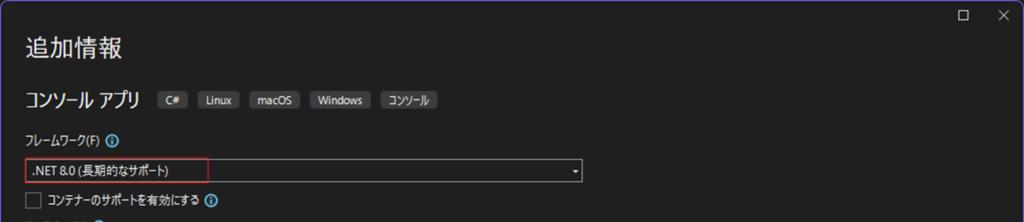
.Netのバージョンは,C++/CLIの設定に合わせて 8.0 と設定します.
今回は「TestConsole」という名前でプロジェクトを作成しました.作成後は以下のように参照の追加から,事前に作成したC++/CLIのプロジェクトを参照追加します.

Program.csには以下のように,自作したCalculatorクラスを使ってベクトル和をGPUで計算するコードを記述しました.正しく依存関係が設定できていれば, ”using CUDA”のようにC++/CLIのプロジェクトで定義した名前空間が認識されます.
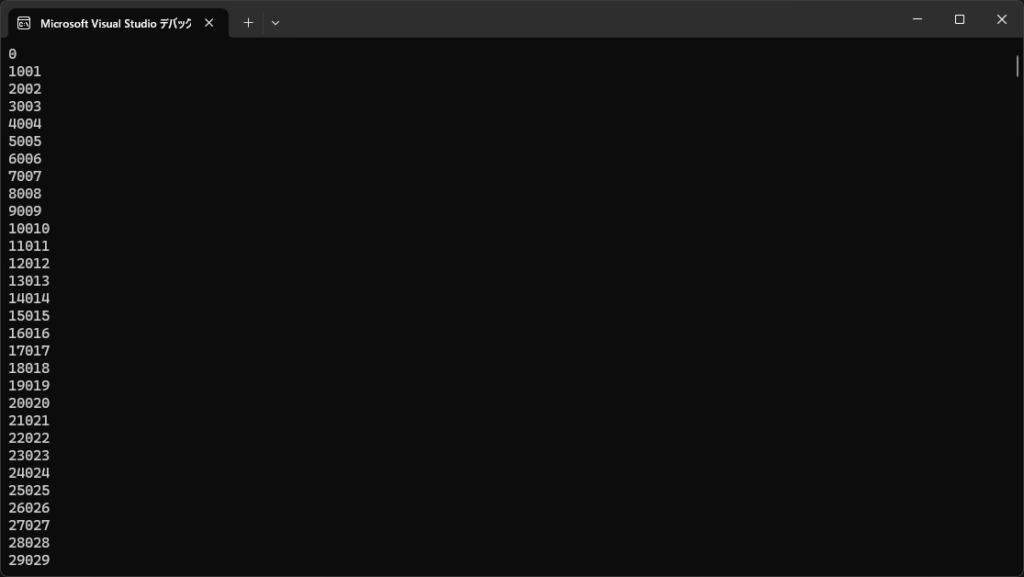
このコードでは,長さ1000のベクトルを用意して,その和を計算します.その後,計算結果のベクトルの要素を順番にコンソール表示しています.
//Program.cs
using CUDA;
using System.Diagnostics;
//ベクトルの長さ
int vectorLength = 1000;
//2つのベクトルを用意
float[] vector0 = new float[vectorLength];
float[] vector1 = new float[vectorLength];
//ベクトルの中身を設定
for(int i = 0; i < vectorLength; i++)
{
vector0[i] = i;
vector1[i] = i * 1000;
}
//GPUでベクトル和を計算
float[] sum = CUDA.Calculator.Add(vector0, vector1);
//コンソール表示
foreach(float value in sum) Console.WriteLine(value); //計算結果以下のように,GPUを使って正しく足し算が実行できていることがわかります.
補足
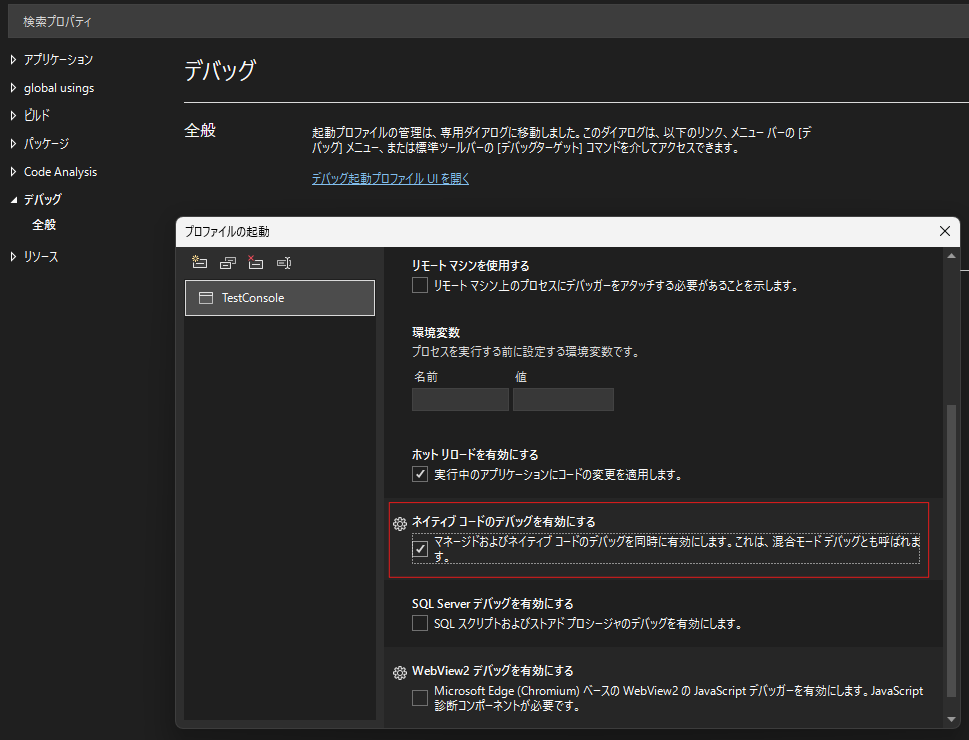
C#のプロジェクト側のプロパティで,下のようにネイティブコードのデバッグを有効にすると,C++/CLIプロジェクトに設定したブレークポイントで停止することができます.